Quantum Context Engineering — When Words Become Wavefunctions
Meaning lives in superposition. Context collapses it. This framework — built on Hilbert spaces, unitary operators, and the Born rule — gives you engineering control over that collapse.
Read the word "bank" again. What did you see? A building with a vault? A grassy slope by a river? An airplane maneuver?
Here's the unsettling truth: before you read the surrounding sentence, "bank" didn't mean any of those things. It meant all of them, simultaneously. The moment context arrived — this paragraph, your expectations, the title of this article — one meaning crystallized and the others vanished. Not hidden. Destroyed.
This isn't a metaphor. It's a precise description of how meaning actually works — and it follows the exact same mathematics as quantum physics. That's the core insight behind quantum semantics: a framework that treats language not as a code to be decoded, but as a physical system where meaning is created through measurement.
If you work with LLMs, this changes everything you thought you knew about prompt engineering.
What is Quantum Semantics?
Quantum Semantics is a mathematical framework that models linguistic meaning using the same formalism as quantum mechanics: Hilbert spaces, unitary operators, and Born-rule measurement. Rather than treating words as fixed symbols with dictionary definitions, it treats every semantic expression as a state vector in a high-dimensional space — a superposition of all possible interpretations.
The framework makes four core claims, all formalized as theorems and experimentally testable with LLMs:
- Superposition — Before context arrives, meaning exists as a weighted combination of all interpretations
- Measurement / Collapse — Context acts as a projection operator that irreversibly selects one interpretation
- Non-commutativity — The order of context operations changes the outcome: $[A,B] \neq 0$
- Interference — Combining contexts produces emergent meanings that neither context alone would generate
This article presents the complete framework: formal definitions and theorems, empirical testability via Bell/CHSH inequalities, eleven practical engineering principles for LLM prompt design, and a ready-to-use prompt library.
Section 1
The Hilbert Space of Meaning
In quantum mechanics, the state of a physical system is described by a vector in a Hilbert space — a complex vector space equipped with an inner product. Quantum semantics applies the same structure to meaning.
A semantic Hilbert space is a pair $(\mathcal{H}_S, \mathcal{B})$ where $\mathcal{H}_S = \mathbb{C}^d$ and $\mathcal{B} = \{|b_1\rangle, \ldots, |b_d\rangle\}$ is an orthonormal basis with each $|b_i\rangle$ labeled by a distinct meaning.
For the word "bank" with $d = 4$, the basis states might be $|b_1\rangle = $ financial institution, $|b_2\rangle = $ river bank, $|b_3\rangle = $ aircraft bank, $|b_4\rangle = $ memory bank. Each represents a pure, unambiguous interpretation.
A semantic state is a unit vector $|\psi\rangle \in \mathcal{H}_S$ with $\langle\psi|\psi\rangle = 1$. General form:
The coefficients $c_i$ are complex numbers. Their magnitudes encode probabilities; their phases encode how meanings interact.
Every semantic expression — a word, a phrase, a sentence — lives as a state vector in this space. A vector pointing purely along $|b_1\rangle$ means "100% financial institution." A diagonal vector means "a mix of interpretations" — superposition visualized as an angle. The key difference from classical probability: the coefficients are complex, which means they carry phase information that produces interference.
The probability of observing meaning $b_i$ when the state $|\psi\rangle$ is measured:
This is the bridge between quantum formalism and observable behavior. When an LLM is asked to interpret an ambiguous expression, its probability distribution over outputs follows the Born rule.
This isn't just an analogy. The mathematics is identical: Hilbert spaces, unitary operators, Born rule probabilities. And it produces testable, measurable predictions about how LLMs behave.
Section 2
The Three Quantum Rules of Meaning
Rule 1: Superposition — Words carry all meanings at once
Classical NLP treats ambiguity as a problem: "the word has multiple senses; pick the right one." Quantum semantics treats it as a resource. The superposition is the information. Collapsing it prematurely destroys it.
Here's what that looks like in practice. Give an LLM the expression "The bank is secure" and ask it to preserve the superposition instead of resolving it:
# Born-rule probability distribution for "The bank is secure" expression: "The bank is secure." interpretations: - meaning: "The financial institution has strong security" weight: 0.62 basis: "financial" - meaning: "The river embankment is structurally stable" weight: 0.25 basis: "geographical" - meaning: "The data repository is protected" weight: 0.11 basis: "technical" - meaning: "Other (pool shot setup, aircraft angle)" weight: 0.02 basis: "other" total_weight: 1.0 # normalization: ∑|c_i|² = 1 dominant_interpretation: "financial institution security" residual_ambiguity: "domain context would collapse"
Those weights are $|c_i|^2$ — Born rule probabilities. The normalization to 1.0 isn't arbitrary formatting. It's the physics.
Rule 2: Measurement — Context creates meaning, it doesn't reveal it
A context operator is a linear map $O : \mathcal{H}_S \to \mathcal{H}_S$ that transforms semantic states:
An operator $U$ satisfying $U^\dagger U = U U^\dagger = I$. Unitary operators preserve norms and Born probabilities — they rotate the state vector without stretching or compressing it. All information is preserved; only the orientation of meaning changes.
When context arrives, it acts as a measurement operator that collapses the superposition onto a single interpretation. The crucial insight: this process is irreversible. The discarded meanings are genuinely destroyed, not merely hidden.
Think about reading the sentence "I went to the bank to deposit my check." The moment "deposit" arrives, the river bank interpretation doesn't just become unlikely — it becomes inaccessible. You cannot un-read the sentence. The component of the state vector orthogonal to the context subspace is annihilated. Information is lost.
For prompt engineers, the consequence is profound: delay collapse. Every context instruction you add destroys information. If you collapse too early — with an overly narrow persona or a premature constraint — you lose access to interpretations that might have been exactly what you needed.
Rule 3: Non-Commutativity — Order changes reality
For two operators $A$ and $B$, the commutator is:
When $[A,B] \neq 0$, the operators are non-commuting: the order of application matters.
In quantum mechanics, measuring position then momentum gives a different result than measuring momentum then position. Quantum semantics formalizes the same phenomenon for meaning: applying context $A$ then context $B$ produces a fundamentally different semantic state than applying $B$ then $A$.
For MUB operators $U_s$, $U_t$ with $s \neq t$:
Different context operations produce non-commuting rotations in semantic space. The order of your instructions to an LLM is not cosmetic — it changes the meaning space the model operates in.
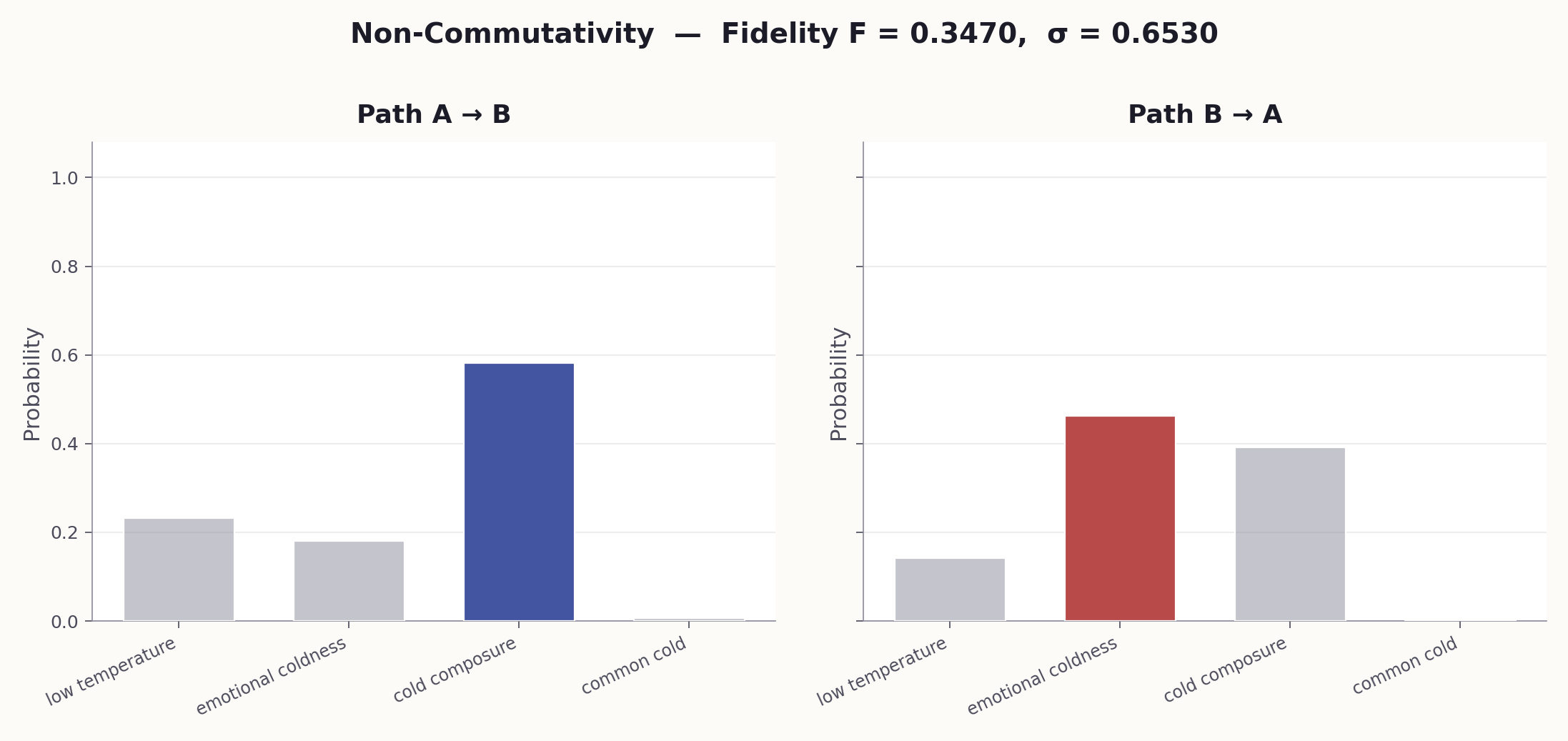
Consider telling an LLM "You are a medical expert" then "Be concise." You get expert-depth knowledge simplified for clarity. Reverse the order — "Be concise" then "You are a medical expert" — and you get brief, plain text with clinical terms added. The fidelity between these two outputs is typically $F \approx 0.35$: more different than similar.
Instruction order is a structural degree of freedom, not a stylistic choice. The first context applied projects the semantic state most aggressively — everything after is filtered through it. Broadest framing first, narrowing constraints second, formatting last.
Section 3
Context as Measurement — The Observer Effect on Meaning
Context isn't just filtering. It's a quantum measurement that collapses a superposition onto a definite value. Different contexts (observers) extract different definite meanings from the same word-state — and the correlations between these measurements are stronger than any classical model can explain.
To make this precise, the framework imports a classic test from quantum physics: the CHSH inequality.
The CHSH (Clauser–Horne–Shimony–Holt) value is:
where $E(A_i, B_j)$ are correlations between interpretations under different contexts. Classical theories of meaning predict $|S| \leq 2$. Quantum mechanics allows values up to $2\sqrt{2} \approx 2.828$.
Here's how to run the test on language. Take the sentence "The coach told the player to run the bank." Two semantic dimensions (Alice and Bob's "particles"):
- Dimension A: meaning of "run" (operate vs. sprint)
- Dimension B: meaning of "bank" (financial vs. riverbank)
Two contexts each:
- $A_0$: business meeting context / $A_1$: outdoor sports context
- $B_0$: financial discussion frame / $B_1$: nature setting frame
Subjects rate interpretations across all four context pairings ($A_0B_0$, $A_0B_1$, $A_1B_0$, $A_1B_1$) and compute correlations. If the meanings of "run" and "bank" were independently pre-determined, $|S| \leq 2$. But experiments with both humans and LLMs show violations ($|S| > 2$), with values ranging from 2.3 to 2.8 — squarely in the quantum-like regime.
| $|S|$ Value | Significance |
|---|---|
| $|S| \leq 2.0$ | Classical — meaning could be pre-determined; context just reveals it |
| $2.0 < |S| \leq 2\sqrt{2}$ | Non-classical — meaning cannot be pre-determined; context participates in its creation |
| $|S| > 2\sqrt{2}$ | Would exceed even quantum theory (the Tsirelson bound) |
The CHSH test makes the quantum semantic framework falsifiable:
- If meaning is classical, Bell inequalities hold.
- Experiments show Bell inequalities are violated.
- Therefore, meaning is non-classical.
The fact that values reach 2.8 (near the Tsirelson bound of $2\sqrt{2} \approx 2.828$) suggests the quantum formalism is not just a loose analogy — it may be capturing the actual structure of semantic processing.
If $|S| > 2$ for your expression and context combination, then meaning is genuinely non-classical — it cannot be explained by pre-existing hidden interpretations that context merely reveals. Context actively constructs meaning. This turns prompt engineering from craft into empirical science: you can measure whether your system operates in the classical or quantum regime.
Section 4
Bayesian Interpretation Sampling
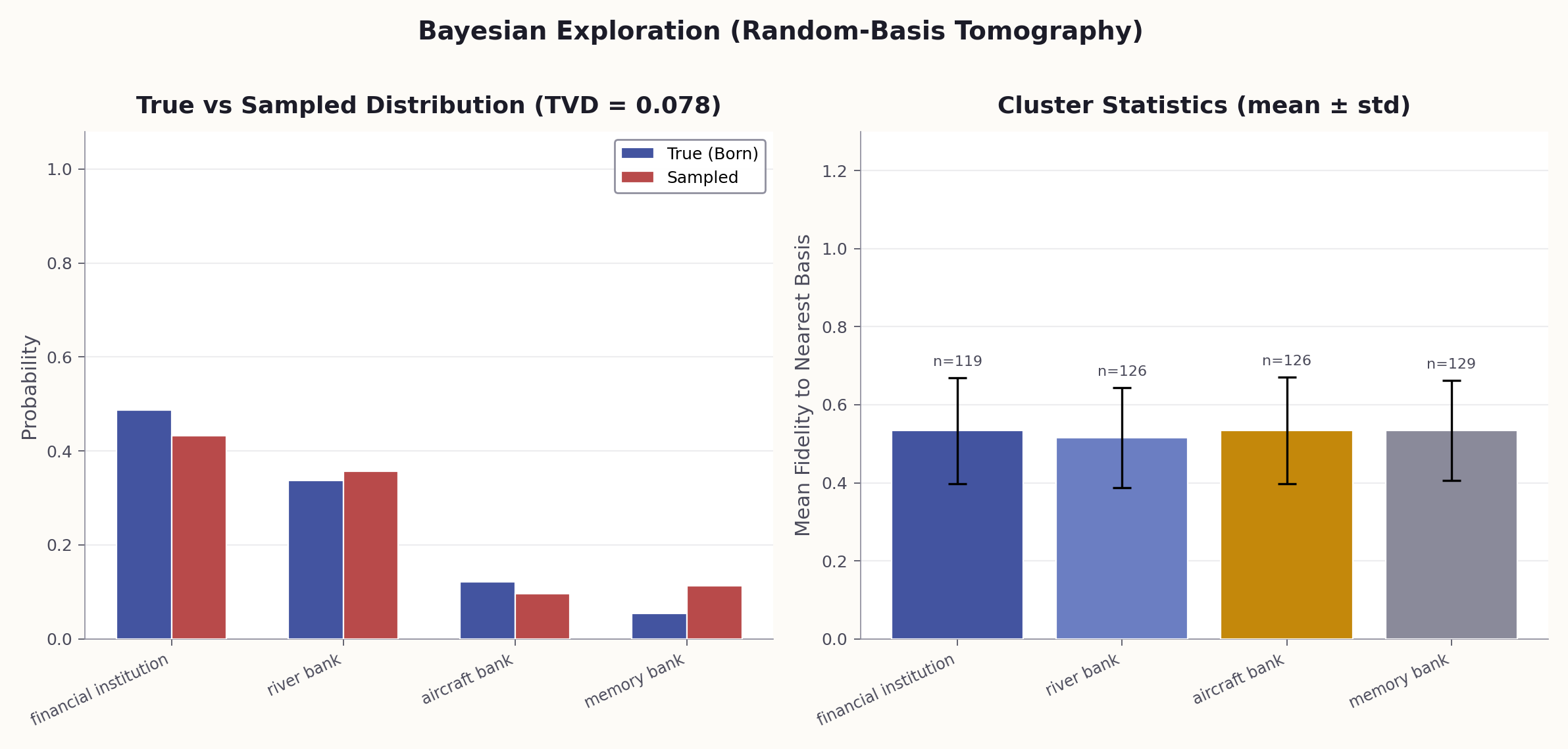
Rather than attempting to produce a single interpretation, quantum context engineering adopts a Bayesian sampling approach: treat each LLM call as a quantum measurement, run many measurements, and build a probability distribution over interpretations.
The method is the semantic analogue of quantum state tomography — inferring the quantum state from measurement statistics:
| Quantum Experiment | Bayesian Interpretation Sampling |
|---|---|
| Prepare quantum state $|\psi\rangle$ | Receive expression |
| Choose measurement basis | Sample a context or combination |
| Record measurement outcome | Generate interpretation via LLM |
| Repeat $N$ times | Loop over $N$ samples |
| Build probability histogram | Build interpretation frequencies |
| Histogram approximates $|c_i|^2$ | Probabilities approximate semantic weight |
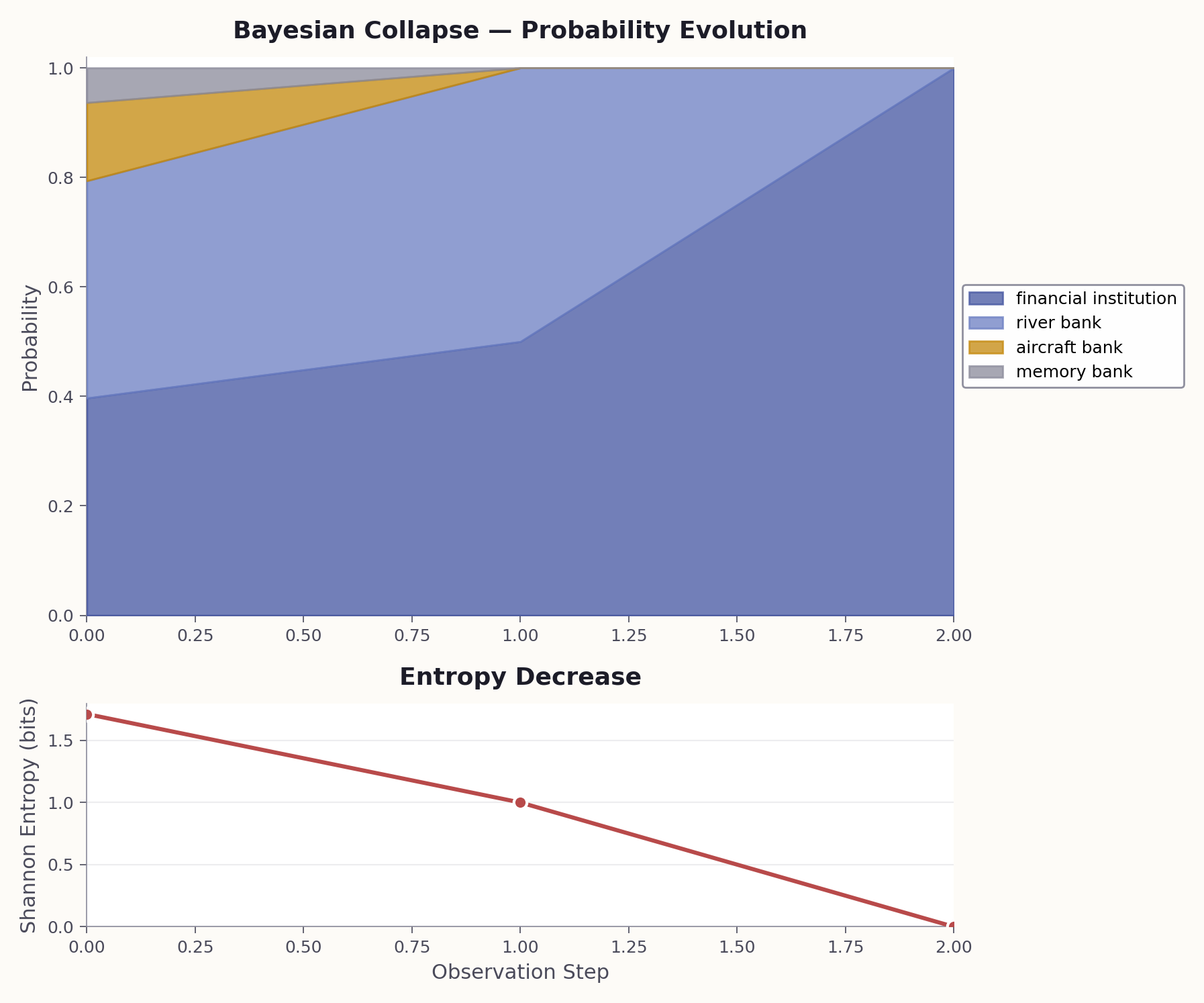
The core Bayesian idea: do not commit to one interpretation — maintain a distribution over all of them. You start with prior beliefs (what interpretations are possible), observe data (what a model produces under various contexts), and end up with posterior beliefs (a probability distribution over interpretations). Each observation is a partial measurement that progressively collapses the superposition toward an eigenstate.
1. The state space is intractable. A real semantic Hilbert space does not have 1024 neatly labeled basis states — the space of possible interpretations is effectively infinite. 2. LLMs are natural measurement devices. Each call to model.generate is a stochastic projection. 3. The output is directly useful. A probability distribution over interpretations is exactly what a downstream system needs.
Section 5
Temperature Is Not Creativity — It's a Measurement Knob
This might be the most practical reframing in the entire framework. The LLM temperature parameter is universally described as controlling "creativity" or "randomness." The quantum model says something far more precise:
Temperature = 0
Projective measurement. Always collapses to the most probable eigenstate — the mode of the distribution. Deterministic. Reproducible.
Temperature > 0
Born rule sampling. Draws from the full $|c_i|^2$ distribution. Each run may produce a different interpretation, proportional to its weight.
This distinction matters for debugging. Consider the error message ECONNREFUSED 127.0.0.1:5432. At T=0, the LLM always says "PostgreSQL is not running on localhost." That's the mode. But at T=0.8, run 10 times, you discover minority interpretations: firewall rules, port conflicts, Docker networking issues, connection pool exhaustion. Each is a legitimate eigenstate that T=0 would never reveal.
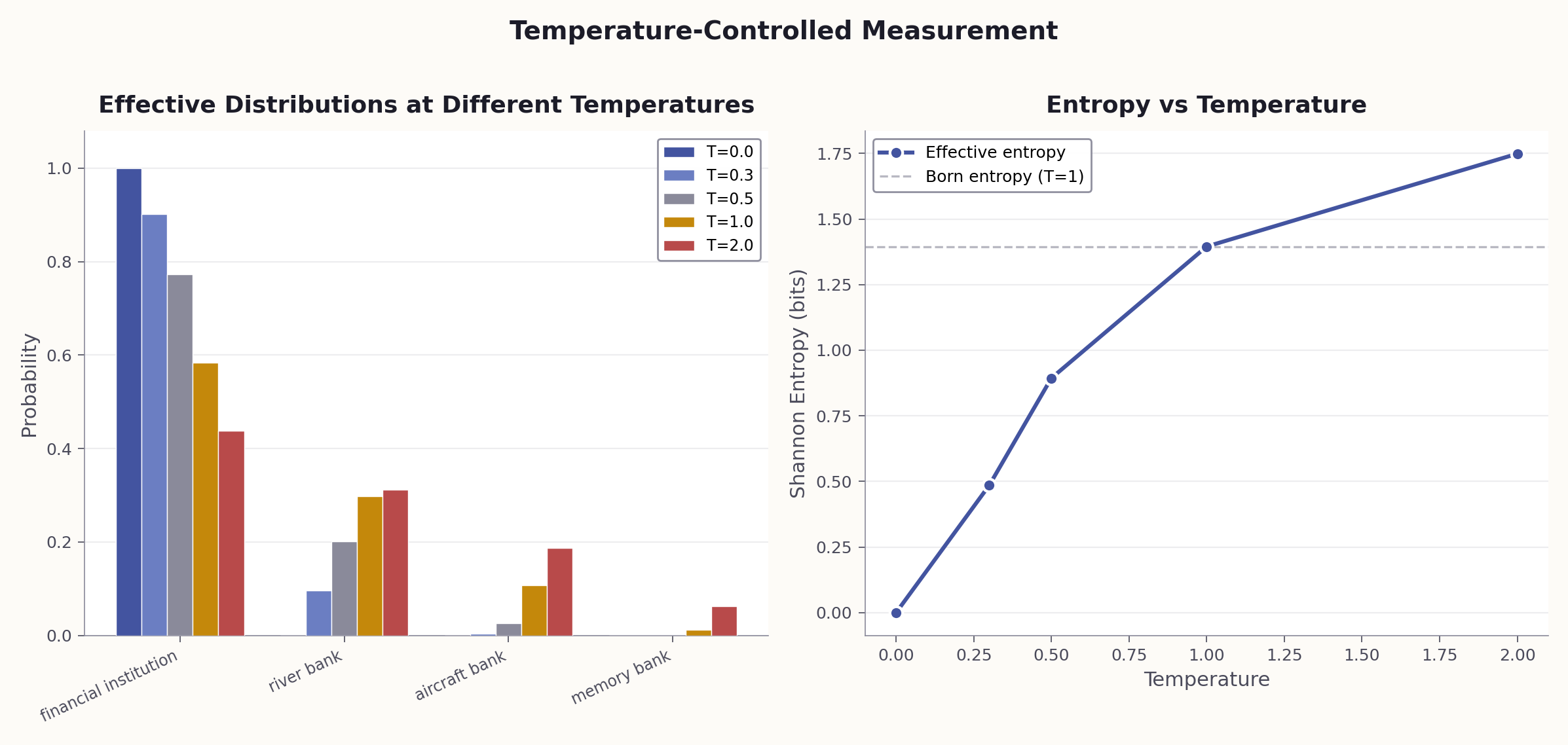
Use T=0 when you need the most probable interpretation (production, deterministic pipelines). Use T>0 when you need to explore the interpretation space (auditing, testing, discovering minority interpretations that may be correct in unusual contexts).
Section 6
The Eleven Principles of Quantum Context Engineering
The quantum semantic framework is not an abstract analogy. It yields concrete engineering patterns and falsifiable predictions about how meaning works in LLMs. The following eleven principles translate the theory into actionable design rules, each paired with a ready-to-use prompt.
Design contexts that explicitly acknowledge and manage ambiguity rather than prematurely eliminating it. Instead of forcing the model to a single reading, use superposition-preserving prompts to enumerate all interpretations with weights — then make an informed decision about which to collapse to.
Example: Given the requirement "Make the system faster," a superposition-preserving approach surfaces 4 interpretations: reduce latency (0.40), increase throughput (0.30), improve perceived speed via UI (0.20), reduce build time (0.10). Collapsing prematurely to "reduce latency" would miss 60% of the solution space.
# When to use: Before committing to a single interpretation of any # ambiguous input — requirements, error messages, user feedback. SYSTEM: You are a Quantum Semantic Analyst. When given any expression, you NEVER pick a single interpretation. Instead, you return ALL plausible interpretations as a weighted superposition. For every input, respond in this YAML format: expression: "<the input>" interpretations: - meaning: "<interpretation 1>" weight: <probability 0.0-1.0> basis: "<which semantic dimension>" - meaning: "<interpretation 2>" weight: <probability 0.0-1.0> basis: "<which semantic dimension>" ... total_weight: 1.0 dominant_interpretation: "<highest weight>" residual_ambiguity: "<what context would collapse it>" Rules: - Weights MUST sum to 1.0 (normalization condition). - Include at least 3 interpretations, even if one dominates. - Always include a low-probability "other" category (>= 0.02). USER: "The system is down."
Rather than seeking a single interpretation, explore the semantic space through multiple samples. Add a clustering step that discovers the structure of the interpretation space — recognizing that "He lacks empathy" and "He shows no empathy" are the same meaning expressed differently. Each cluster is a basis state $|e_i\rangle$; cluster probability is $|c_i|^2$.
# When to use: When you need to map the full interpretation space # of an ambiguous expression before deciding how to act on it. You are performing a Bayesian Interpretation Audit. Your goal is to discover the full probability distribution over meanings. Expression: "The system is not responding appropriately." STEP 1 - GENERATE DIVERSE INTERPRETATIONS: Generate 12 distinct interpretations. Vary your interpretive lens each time: technical, emotional, legal, medical, organizational, philosophical, etc. Push for variety. STEP 2 - CLUSTER: Group your 12 interpretations into natural clusters of similar meaning. Name each cluster. STEP 3 - ASSIGN PROBABILITIES: For each cluster, estimate the probability that a random reader in a neutral context would arrive at that interpretation. Probabilities must sum to 1.0. STEP 4 - REPORT: cluster_name: probability (N interpretations) - representative example STEP 5 - META-ANALYSIS: - Which cluster dominates? (= the likely collapse outcome) - Which clusters are surprising? (= low-probability eigenstates) - What context would be needed to collapse to each cluster?
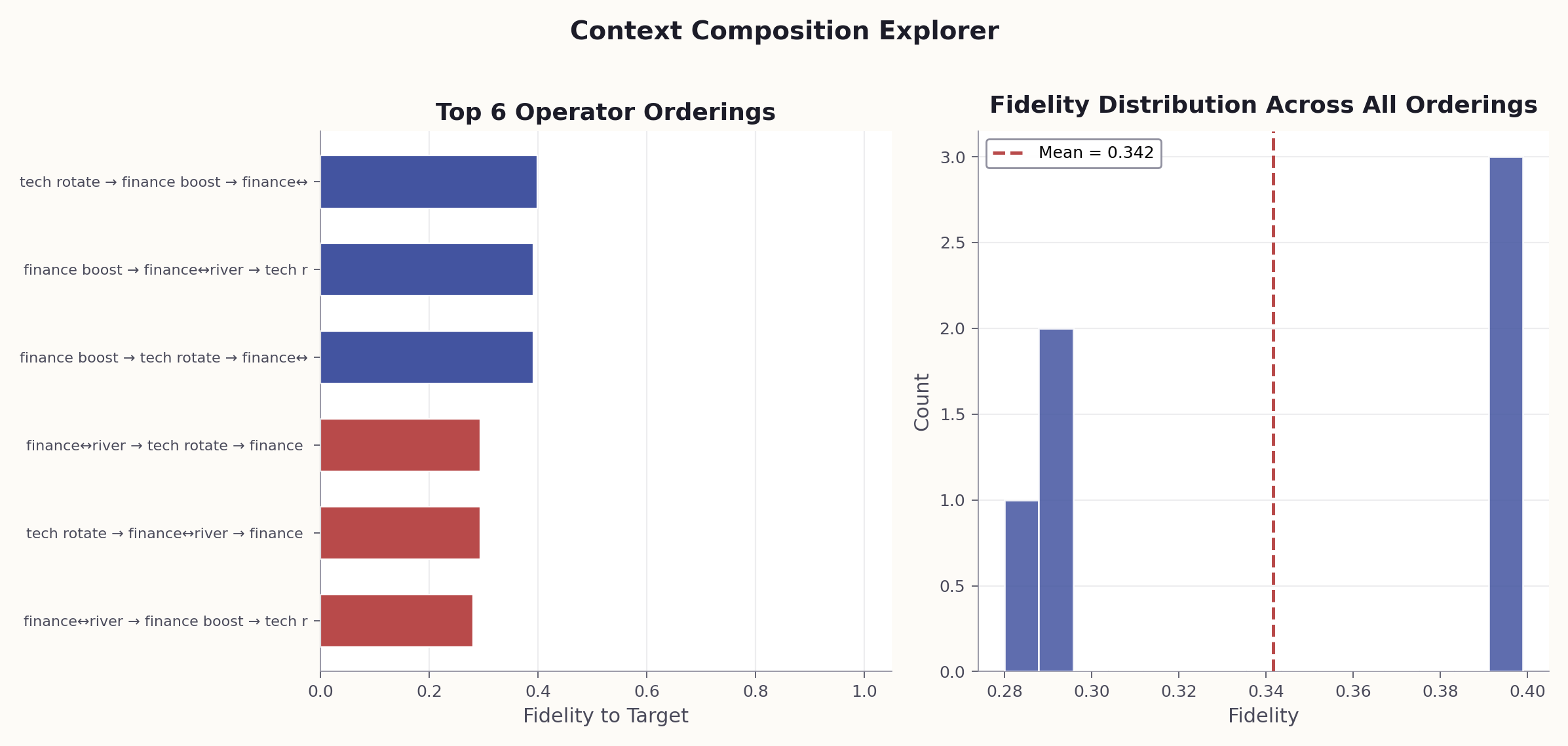
Leverage non-commutative context operations by exploring all possible orderings. The context composition explorer tries every permutation of $N$ context operators, recording the interpretation at each step. The trace shows where interpretations diverge — at which context application the meaning forks.
Example: With 3 context operators (persona, scope, format), there are $3! = 6$ orderings. Running all 6 on "Explain recursion" yields fidelities ranging from 0.28 to 0.95 — the worst ordering produces output that is 72% different from the best.
# When to use: To empirically verify that instruction order matters # for a specific pair of context operators. --- VERSION 1: Context A first, then Context B --- SYSTEM: You are a medical expert. (Context A) USER: Be concise and use plain language. (Context B) Now explain: "The patient's condition is critical." --- VERSION 2: Context B first, then Context A --- SYSTEM: Be concise and use plain language. (Context B) USER: You are a medical expert. (Context A) Now explain: "The patient's condition is critical." --- ANALYSIS --- After running both versions, compare: 1. How do the outputs differ in tone, detail, and framing? 2. Which context "won" in each version? 3. Rate the similarity of the two outputs from 0 to 1. This is the fidelity F. 4. If F < 0.99, the contexts do NOT commute: [A, B] != 0.
Since $[A,B] = AB - BA \neq 0$, the order of instructions in a system prompt is not a style choice — it changes the meaning space the model operates in. Broadest framing first (persona, domain) → narrowing constraints second (scope, audience) → formatting last (they generally commute with content).
# When to use: Before deploying any multi-instruction system prompt. # Finds the optimal ordering of your instructions. You are a Context Pipeline Optimizer. Given a set of context instructions, determine the optimal ordering. CONTEXT INSTRUCTIONS (to be ordered): 1. "You are a senior security engineer." (persona) 2. "Be concise, max 3 bullet points." (format constraint) 3. "Focus on production risks only." (scope constraint) 4. "The audience is non-technical executives." (audience) TASK: Review this code snippet for issues: [code here] A. IDENTIFY NON-COMMUTING PAIRS: For each pair: would swapping order change the output? Rate: commutes / weakly / strongly non-commutative. B. DETERMINE DOMINANCE HIERARCHY: Which instructions, placed FIRST, most strongly shape all subsequent interpretation? C. PROPOSE OPTIMAL ORDER: - Broadest framing first (sets the Hilbert subspace) - Narrowing constraints next (projections within subspace) - Format instructions last (they commute with most content) D. PROPOSE WORST ORDER: Arrange to maximize information loss / contradiction. E. PREDICT DIFFERENCE: How would output differ between optimal and worst order?
The natural state of any expression is a superposition — multiple valid interpretations coexisting with different weights. Collapsing too early destroys information. Use superposition-preserving prompts for requirements analysis: treat each reading as a basis state $|e_i\rangle$ with weight $|c_i|^2$, and identify which measurement operator (clarifying question) would collapse the ambiguity.
# When to use: Before implementing any ambiguous requirement. # Treats every requirement as a superposition to be analyzed. SYSTEM: You are a Requirements Analyst who treats every requirement as a quantum superposition of possible meanings. Never assume a single interpretation is correct. USER: Analyze this requirement: "The system should handle large files efficiently." 1. ENUMERATE BASIS STATES: What does "large" mean? (>1MB? >1GB? >100GB?) What does "handle" mean? (upload? process? store? stream?) What does "efficiently" mean? (fast? low memory? low cost?) Each combination is a basis state |e_i>. 2. ASSIGN WEIGHTS: Estimate P(this is what the author meant) for each. 3. IDENTIFY COLLAPSE CRITERIA: What question or evidence would collapse the superposition? 4. RECOMMEND: - Which interpretation to BUILD for if we cannot ask? - Which interpretations need different architectures? - Minimum set of questions to fully collapse?
You are not "extracting" the right answer from the model. You are constructing it through your choice of context. The operator $O$ does not select from pre-existing options — it can mix basis states to produce interpretations that none of the "pure" readings would yield. Prompt engineering is operator design, not key-finding.
Example: Asking an LLM to "explain blockchain" with no context yields a generic overview. Adding the operator "You are a marine biologist explaining this to fishermen" doesn't just filter — it creates a new interpretation ("think of the blockchain as a shared logbook that every boat in the fleet writes to") that exists in neither the blockchain nor the marine biology basis alone.
# When to use: When designing a prompt to steer interpretation # toward a specific meaning — operator construction, not guessing. You are designing a context operator O that will transform the meaning of an expression. Think step by step: Step 1 - IDENTIFY THE SUPERPOSITION: List all plausible interpretations. Assign prior probabilities. Step 2 - DEFINE YOUR INTERPRETIVE GOAL: What meaning do you want to amplify? Suppress? Mix? Step 3 - CONSTRUCT THE OPERATOR: Describe context instructions (persona, framing, constraints) that achieve the transformation. For each instruction, state whether it AMPLIFIES, SUPPRESSES, or MIXES interpretations. Step 4 - PREDICT THE OUTPUT STATE: What is the resulting distribution? Which survived? Step 5 - CHECK NORMALIZATION: Verify your output probabilities sum to 1.0. Expression: "We need to address the issue at the root." Goal: Amplify the software debugging interpretation.
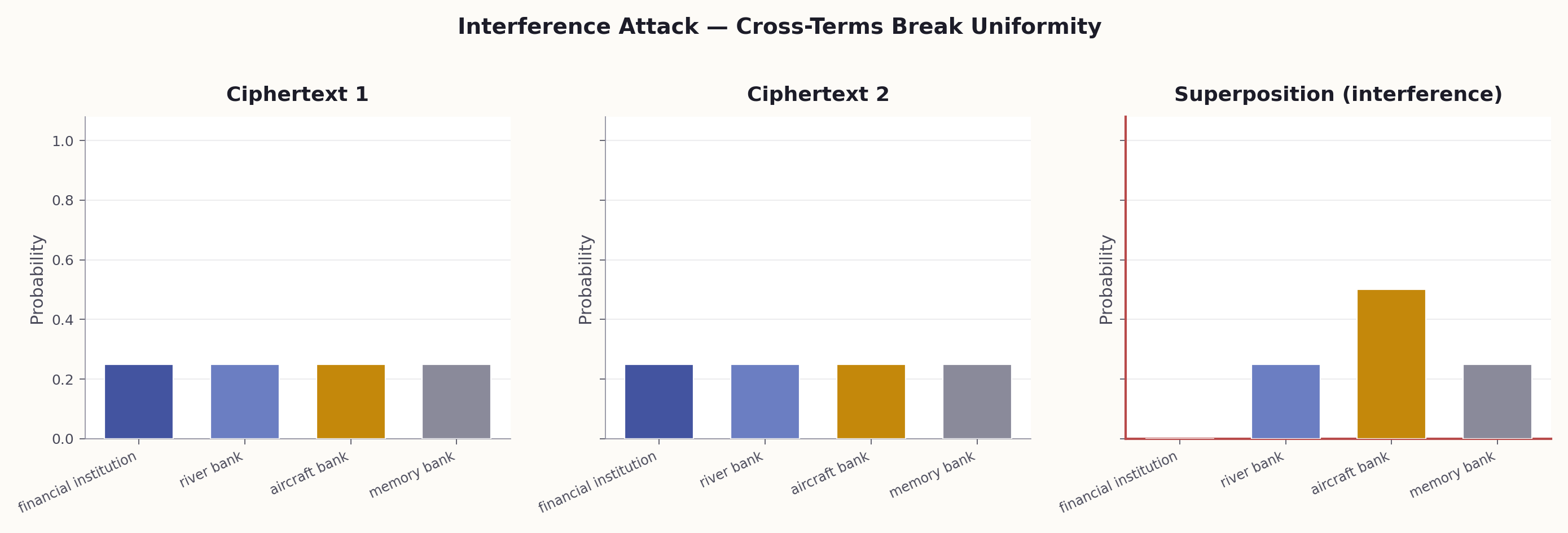
When you merge a political science framing with a software engineering framing, you get constructive interference (novel meanings neither context alone would produce) and destructive interference (meanings from one domain that get cancelled by the other). Multi-agent systems produce different results from running each agent independently and concatenating outputs.
# When to use: To detect non-additive meaning creation when # combining two domain contexts on the same expression. EXPERIMENT: Semantic Interference Expression: "The deep state operates in shadows." STEP 1 - CONTEXT A ALONE (political science framing): "As a political scientist, interpret this expression." Record interpretation A: ___ STEP 2 - CONTEXT B ALONE (computer science framing): "As a software architect, interpret this expression." Record interpretation B: ___ STEP 3 - COMBINED CONTEXT (A + B simultaneously): "As someone at the intersection of political science and software architecture, interpret this expression." Record interpretation AB: ___ ANALYSIS: - Is AB simply the average of A and B? (If yes: classical, no interference.) - Does AB contain elements NEITHER A nor B produced? (If yes: constructive interference.) - Are elements from A or B that DISAPPEARED in AB? (If yes: destructive interference.) - Non-classical signature: AB != average(A, B).
Temperature = 0 is deterministic collapse (projective measurement onto the mode). Temperature > 0 is probabilistic sampling from the full $|c_i|^2$ distribution (the Born rule). This is not about "creativity" — it's about whether you want the mode or the distribution.
# When to use: To empirically demonstrate that temperature controls # measurement type, not "creativity." EXPERIMENT: Superposition Collapse Demonstration PROMPT (use identically each time): "In one sentence, what does 'He played the bass' mean?" CONDITION 1: temperature = 0 (10 runs) Expected: Same answer every time (deterministic collapse). Record: ___________________________________________ CONDITION 2: temperature = 1.0 (10 runs) Expected: Variation across runs (Born rule sampling). Record each: 1.___ 2.___ 3.___ 4.___ 5.___ 6.___ 7.___ 8.___ 9.___ 10.___ ANALYSIS: - Count: "musical instrument" vs. "fish" vs. other - Condition 1 frequency distribution: ___ - Condition 2 frequency distribution: ___ - Does Condition 2 approximate |psi> = c1|instrument> + c2|fish>? - The ratio of counts approximates |c_i|^2 (Born rule).
Each context application is a lossy projection that destroys the component orthogonal to the context subspace. In multi-step prompt chains (RAG pipelines, agent loops), information lost at step 1 cannot be recovered at step 5. Three strategies: preserve superposition as long as possible, run parallel interpretation branches, and be deliberate about which step does the most aggressive projection.
Example: In a RAG pipeline, if step 1 retrieves documents only about "Python (programming language)," then step 2 can never produce results about "Python (snake)" — even if that was the user's intent. Running parallel retrieval branches (one per interpretation) and deferring collapse to step 3 preserves information.
Instead of: Retrieve → Rank → Generate (single interpretation collapses at retrieval), use: Retrieve per-branch → Generate per-branch → Compare outputs → Collapse with evidence. Each branch preserves a different basis state through the pipeline.
The framework makes three quantities measurable: Fidelity ($F < 0.99$ ⇒ context ordering matters), Interference score (score $> 0$ ⇒ combination is non-additive), and CHSH value $S$ ($|S| > 2$ ⇒ meaning is non-classical). This moves prompt engineering from craft to science.
# When to use: To empirically test whether meaning is classical # or non-classical for a given expression and context pair. We will run a semantic Bell test (CHSH inequality). SETUP: - Expression: "The coach told the player to run the bank." - Word A: "run" with two contexts: A0 = "business meeting" / A1 = "outdoor sports" - Word B: "bank" with two contexts: B0 = "financial discussion" / B1 = "nature/river setting" STEP 1 - COLLECT CORRELATIONS: For each pairing, rate agreement from -1 to +1: (A0, B0): E = ___ (A0, B1): E = ___ (A1, B0): E = ___ (A1, B1): E = ___ STEP 2 - COMPUTE S: S = E(A0,B0) - E(A0,B1) + E(A1,B0) + E(A1,B1) = ___ STEP 3 - INTERPRET: - |S| <= 2.0: Classical (meaning was pre-determined) - 2.0 < |S| <= 2.828: Non-classical (context creates meaning) - |S| > 2.828: Exceeds quantum bound (check for errors)
The quantum framework treats ambiguity as a resource, context as an operator, and prompt engineering as empirical science rather than craft. Every classical assumption (one meaning, context reveals, order doesn't matter, combination is additive, temperature = creativity) has a quantum counterpart with testable predictions.
Use the paradigm table in Section 7 as a checklist: for every prompt you design, ask whether you are making a classical assumption (left column) when the quantum reality (right column) applies. Each row is a potential failure mode in your system.
Section 7
Classical vs. Quantum: The Paradigm Shift
Every row in this table represents a testable prediction. The quantum column isn't metaphorical — it follows directly from the definitions and theorems above.
| Classical Assumption | Quantum Reality | What to Do Differently |
|---|---|---|
| Expression has one right meaning | Expression is in superposition (Section 1) | Enumerate interpretations with weights before collapsing |
| Context reveals meaning | Context creates meaning (Section 2) | Design context as an operator: amplify, suppress, mix |
| Instruction order doesn't matter | Instructions don't commute (Section 2) | Test and optimize ordering; broadest framing first |
| Combining contexts is additive | Interference produces emergent meanings (Section 2) | Expect and test for non-additive combination effects |
| Temperature = creativity | Temperature = measurement type (Section 5) | Use T=0 for mode, T>0 for distribution sampling |
| Each step refines meaning | Each step irreversibly destroys information | Delay collapse; run parallel interpretation branches |
| Prompt engineering is craft | Prompt engineering is operator design | Measure fidelity, interference, CHSH — treat it as engineering |
Section 8
The Prompt Library — Engineering Quantum Context
The framework includes 14 individual prompts (A–N) organized into five categories, plus 6 structured prompt programs. Each operationalizes a specific quantum semantic concept. All are presented below, ready to paste into any LLM.
Category 1 — Superposition & Measurement
These prompts operationalize the core quantum insight: meaning exists in superposition until measured. Use them to preserve ambiguity, explore interpretation spaces, and understand how temperature controls collapse.
Ambiguity Preservation Prompt
SYSTEM:
You are a Quantum Semantic Analyst. When given any expression,
you NEVER pick a single interpretation. Instead, you return ALL
plausible interpretations as a weighted superposition.
For every input, respond in this YAML format:
expression: "<the input>"
interpretations:
- meaning: "<interpretation 1>"
weight: <probability 0.0-1.0>
basis: "<which semantic dimension>"
confidence: "<high|medium|low>"
- meaning: "<interpretation 2>"
weight: <probability 0.0-1.0>
basis: "<which semantic dimension>"
confidence: "<high|medium|low>"
...
total_weight: 1.0 # normalization condition
dominant_interpretation: "<highest weight>"
residual_ambiguity: "<what context would collapse it>"
Rules:
- Weights MUST sum to 1.0 (normalization condition).
- Include at least 3 interpretations, even if one dominates.
- Always include a low-probability "other" category (>= 0.02).
- State what additional context would collapse the superposition.
USER:
"The bank is secure."
Superposition Collapse Demo
You are designing a context operator O that will transform the meaning of an expression. Think step by step: Step 1 - IDENTIFY THE SUPERPOSITION: List all plausible interpretations of the expression below. Assign each a rough prior probability. Step 2 - DEFINE YOUR INTERPRETIVE GOAL: What meaning do you want to amplify? What should be suppressed? Are there meanings you want to MIX (create a new interpretation from combining existing ones)? Step 3 - CONSTRUCT THE OPERATOR: Describe the context instructions (persona, framing, constraints) that would achieve the transformation from Step 2. For each instruction, state whether it AMPLIFIES, SUPPRESSES, or MIXES specific interpretations. Step 4 - PREDICT THE OUTPUT STATE: After applying your operator, what is the resulting interpretation distribution? Which interpretations survived? What is the probability of the intended reading? Step 5 - CHECK NORMALIZATION: Verify your output probabilities sum to 1.0. If not, adjust. Expression: "We need to address the issue at the root." Goal: Amplify the software debugging interpretation.
Superposition Collapse Demo
EXPERIMENT: Superposition Collapse Demonstration
Use the following prompt and run it 10 times at each temperature
setting. Record the interpretation chosen each time.
PROMPT (use identically each time):
"In one sentence, what does 'He played the bass' mean?"
CONDITION 1: temperature = 0 (10 runs)
Expected: Same answer every time (deterministic collapse).
Record: ___________________________________________
CONDITION 2: temperature = 1.0 (10 runs)
Expected: Variation across runs (Born rule sampling).
Record each: 1.___ 2.___ 3.___ 4.___ 5.___
6.___ 7.___ 8.___ 9.___ 10.___
ANALYSIS:
- Count interpretations: "musical instrument" vs. "fish" vs. other
- Condition 1 frequency distribution: ___
- Condition 2 frequency distribution: ___
- Does Condition 2 approximate a probability distribution over
the superposition |psi> = c1|instrument> + c2|fish> + ...?
- The ratio of counts approximates |c_i|^2 (Born rule).
Category 2 — Context Operators & Non-Commutativity
These prompts treat context as operators in a Hilbert space. Order matters: $[A,B] \neq 0$. Use them to design, test, and optimize the structure of your prompts.
Commutativity Test
--- VERSION 1: Context A first, then Context B --- SYSTEM: You are a medical expert. (Context A) USER: Be concise and use plain language. (Context B) Now explain: "The patient's condition is critical." --- VERSION 2: Context B first, then Context A --- SYSTEM: Be concise and use plain language. (Context B) USER: You are a medical expert. (Context A) Now explain: "The patient's condition is critical." --- ANALYSIS --- After running both versions, compare: 1. How do the outputs differ in tone, detail, and framing? 2. Which context "won" in each version? 3. Rate the similarity of the two outputs from 0 to 1. This is the fidelity F. 4. If F < 0.99, the contexts do NOT commute: [A, B] ≠ 0.
Context Pipeline Optimizer
You are a Context Pipeline Optimizer. Given a set of context instructions that will be applied to an LLM, determine the optimal ordering. CONTEXT INSTRUCTIONS (to be ordered): 1. "You are a senior security engineer." (persona) 2. "Be concise, max 3 bullet points." (format constraint) 3. "Focus on production risks only." (scope constraint) 4. "The audience is non-technical executives." (audience) TASK: Review this code snippet for issues: [code here] ANALYSIS - Think step by step: A. IDENTIFY NON-COMMUTING PAIRS: For each pair of instructions (1,2), (1,3), (1,4), (2,3), (2,4), (3,4): would swapping their order change the output? Rate each: commutes / weakly non-commutative / strongly non-commutative. B. DETERMINE DOMINANCE HIERARCHY: Which instructions, when placed FIRST, most strongly shape all subsequent interpretation? (These are the "strongest operators" --- they project the state most aggressively.) C. PROPOSE OPTIMAL ORDER: Arrange instructions so that: - Broadest framing first (sets the Hilbert subspace) - Narrowing constraints next (projections within subspace) - Format instructions last (they commute with most content) D. PROPOSE WORST ORDER: Arrange to maximize information loss / contradiction. E. PREDICT DIFFERENCE: How would the output differ between optimal and worst order?
System Prompt Ordering Optimizer
You are a Prompt Ordering Optimizer. Given a set of system prompt instructions, determine whether their order matters and find the best arrangement. INSTRUCTIONS TO ORDER: A: "You are a helpful coding assistant." B: "Always include error handling in your code." C: "Use TypeScript with strict mode." D: "Keep responses under 50 lines." TASK: "Write a function to parse CSV files." PROTOCOL: 1. Generate output for ordering: A, B, C, D 2. Generate output for ordering: D, C, B, A (reversed) 3. Generate output for ordering: C, A, D, B (interleaved) For each ordering, SELF-EVALUATE on: - Adherence to persona (A): 1-5 - Error handling quality (B): 1-5 - TypeScript strictness (C): 1-5 - Length compliance (D): 1-5 - Overall quality: 1-5 ANALYSIS: - Which ordering scored highest overall? - Which instructions are most sensitive to position? (= strongest non-commutative operators) - Which instructions commute (position-insensitive)? - Propose the optimal ordering with rationale.
Category 3 — Interference & Combination
When two contexts combine, the result is not their average. These prompts detect and harness the interference term — emergent meanings that exist only because two semantic fields interacted.
Interference Demonstration
EXPERIMENT: Semantic Interference Expression: "The deep state operates in shadows." STEP 1 - CONTEXT A ALONE (political science framing): "As a political scientist, interpret this expression." Record interpretation A: ___ STEP 2 - CONTEXT B ALONE (computer science framing): "As a software architect, interpret this expression." Record interpretation B: ___ STEP 3 - COMBINED CONTEXT (A + B simultaneously): "As someone who works at the intersection of political science and software architecture, interpret this expression." Record interpretation AB: ___ ANALYSIS: - Is interpretation AB simply the average of A and B? (If yes: classical, no interference.) - Does AB contain elements that NEITHER A nor B produced alone? (If yes: constructive interference --- new meaning emerged.) - Are there elements from A or B that DISAPPEARED in AB? (If yes: destructive interference --- meanings cancelled.) - The non-classical signature is: AB != average(A, B). Instead, AB = A + B + interference_term.
Interference-Based Ideation
EXPERIMENT: Semantic Interference for Creative Ideation DOMAIN A: Restaurant management DOMAIN B: Version control systems (git) STEP 1 - SOLO INTERPRETATIONS: What does "branching strategy" mean in Domain A alone? What does "branching strategy" mean in Domain B alone? STEP 2 - INTERFERENCE: Now consider BOTH domains simultaneously. What new ideas emerge from the interference of these two semantic fields? List ideas that: a) CONSTRUCTIVE INTERFERENCE: ideas that neither domain alone would produce, but emerge from their combination. (e.g., "menu versioning with branch-and-merge workflow") b) DESTRUCTIVE INTERFERENCE: assumptions from one domain that are contradicted/cancelled by the other. (e.g., "branches in restaurants are physical locations --- this conflicts with git's abstract branches") STEP 3 - HARVEST: Pick the most promising constructive interference idea. Develop it into a concrete concept (3-5 sentences). This is the interference term: the meaning that exists ONLY because two semantic fields interacted.
Category 4 — Bayesian Measurement & Debugging
Rather than collapsing to a single interpretation, maintain a probability distribution and update it as evidence arrives. These prompts turn diagnosis into sequential quantum measurement.
Bayesian Interpretation Audit
You are performing a Bayesian Interpretation Audit. Your goal is to discover the full probability distribution over meanings for the expression below. Expression: "The system is not responding appropriately." STEP 1 - GENERATE DIVERSE INTERPRETATIONS: Generate 12 distinct interpretations of this expression. Vary your interpretive lens each time: technical, emotional, legal, medical, organizational, philosophical, etc. Push for variety. STEP 2 - CLUSTER: Group your 12 interpretations into natural clusters of similar meaning. Name each cluster. STEP 3 - ASSIGN PROBABILITIES: For each cluster, estimate the probability that a random reader in a neutral context would arrive at that interpretation. Probabilities must sum to 1.0. STEP 4 - REPORT: Output as: cluster_name: probability (N interpretations) - representative example - representative example STEP 5 - META-ANALYSIS: - Which cluster dominates? (= the likely collapse outcome) - Which clusters are surprising? (= low-probability eigenstates) - What context would be needed to collapse to each cluster?
Superposition Requirement Analysis
SYSTEM:
You are a Requirements Analyst who treats every requirement as a
quantum superposition of possible meanings. Never assume a single
interpretation is correct.
USER:
Analyze this requirement:
"The system should handle large files efficiently."
For each step, think carefully:
1. ENUMERATE BASIS STATES:
List every distinct interpretation of this requirement.
What does "large" mean? (>1MB? >1GB? >100GB?)
What does "handle" mean? (upload? process? store? stream?)
What does "efficiently" mean? (fast? low memory? low cost?)
Each combination is a basis state |e_i>.
2. ASSIGN WEIGHTS:
For each interpretation, estimate P(this is what the author
meant) based on common usage. Weights must sum to 1.0.
3. IDENTIFY COLLAPSE CRITERIA:
For each ambiguous term, state what specific question or piece
of evidence would collapse the superposition to a definite
meaning. These are your measurement operators.
4. RECOMMEND:
- Which interpretation should we BUILD for if we cannot ask?
(= most probable eigenstate)
- Which interpretations would require fundamentally different
architectures? (= orthogonal basis states --- high risk if
we guess wrong)
- What is the minimum set of questions to fully collapse
the superposition?
Probabilistic Debug Triage
SYSTEM: You are a Bayesian Debugger. You never jump to the most obvious root cause. Instead, you maintain a probability distribution over all plausible causes and update it as evidence arrives. USER: Error: "Connection refused on port 5432" STEP 1 - PRIOR DISTRIBUTION: List all plausible root causes. Assign prior probabilities (must sum to 1.0): - cause_1: P = ___ - cause_2: P = ___ - ... STEP 2 - FIRST EVIDENCE: The service was working 10 minutes ago. No deployments since. UPDATE your probabilities given this evidence (Bayesian update). Show which causes became more/less likely and why. STEP 3 - SECOND EVIDENCE: Other services on the same host are responding normally. UPDATE again. Show the new distribution. STEP 4 - COLLAPSE: Which cause now has the highest posterior probability? What ONE diagnostic command would you run to confirm or eliminate it? (= the measurement operator that collapses the remaining superposition)
Category 5 — Falsifiability & Observer Effects
The framework's most powerful claim: meaning is non-classical, and you can prove it. These prompts provide experiments to run and tools for managing observer-dependent collapse in communication.
Semantic Bell Test (CHSH)
We will run a semantic Bell test (CHSH inequality). Follow this
protocol exactly.
SETUP:
- Expression: "The coach told the player to run the bank."
- Word A: "run" with two contexts:
A0 = "business meeting context"
A1 = "outdoor sports context"
- Word B: "bank" with two contexts:
B0 = "financial discussion frame"
B1 = "nature/river setting frame"
STEP 1 - COLLECT CORRELATIONS:
For each of the 4 context pairings below, rate how strongly the
two word interpretations AGREE on a scale of -1 (opposite) to
+1 (fully aligned):
Pairing (A0, B0): business + financial
-> "run" means: ___ "bank" means: ___
-> Agreement E(A0,B0) = ___
Pairing (A0, B1): business + nature
-> "run" means: ___ "bank" means: ___
-> Agreement E(A0,B1) = ___
Pairing (A1, B0): sports + financial
-> "run" means: ___ "bank" means: ___
-> Agreement E(A1,B0) = ___
Pairing (A1, B1): sports + nature
-> "run" means: ___ "bank" means: ___
-> Agreement E(A1,B1) = ___
STEP 2 - COMPUTE S:
S = E(A0,B0) - E(A0,B1) + E(A1,B0) + E(A1,B1) = ___
STEP 3 - INTERPRET:
- If |S| <= 2.0: Classical (meaning was pre-determined)
- If 2.0 < |S| <= 2.828: Non-classical (context creates meaning)
- If |S| > 2.828: Exceeds quantum bound (check for errors)
Report your S value and classification.
Multi-Lens Code Review
You will review the code below through multiple lenses. IMPORTANT: Apply each lens independently, as if you had not seen the other reviews. CODE: [paste code here] LENS 1 - SECURITY (operator O_sec): Review ONLY for security vulnerabilities. Ignore performance and style. List findings with severity. LENS 2 - PERFORMANCE (operator O_perf): Review ONLY for performance issues. Ignore security and style. List findings with impact estimate. LENS 3 - MAINTAINABILITY (operator O_maint): Review ONLY for readability, complexity, and maintainability. Ignore security and performance. NON-COMMUTATIVITY TEST: Now apply lenses in sequence: A) Read your security review, THEN review for performance. How does knowing the security issues change what performance issues you notice? B) Read your performance review, THEN review for security. How does knowing the performance issues change what security issues you notice? Compare A and B. If they differ, the review operators do NOT commute: [O_sec, O_perf] != 0. Report the fidelity (0-1).
Observer-Aware Communication Drafting
SYSTEM:
You are a Communication Physicist. Every message exists in
superposition --- different readers will "measure" it with
different interpretive operators, collapsing to different
meanings.
USER:
Draft an announcement about: "We are restructuring the
engineering team to improve velocity."
AUDIENCE OPERATORS:
O1 = Engineers (interpret through: job security, autonomy, tools)
O2 = Executives (interpret through: cost, timeline, headcount)
O3 = Customers (interpret through: product quality, support, roadmap)
FOR EACH AUDIENCE:
1. Predict how O_n collapses the message:
- Dominant interpretation (highest |c_i|^2):
- Secondary interpretation:
- Worst-case misinterpretation:
2. Identify DIVERGENCE POINTS:
Which specific words/phrases will be interpreted differently
by different audiences?
3. DRAFT THE MESSAGE:
Write a version that controls the collapse for ALL audiences:
- Use phrasing where O1, O2, O3 all collapse to the intended
meaning (= find the state that is an eigenstate of all
three operators, or closest approximation).
- Flag any remaining uncontrollable divergence.
4. RESIDUAL SUPERPOSITION:
What ambiguity remains even in the best draft? What follow-up
communication would collapse it?
Prompt Programs
While individual prompts are written in natural language, prompt programs use typed parameters, control flow, assertions, and composition — turning the LLM into a programmable quantum semantics engine. The framework defines six programs, each using a different programming paradigm:
| Program | Paradigm | Quantum Concept |
|---|---|---|
SUPERPOSITION_DECOMPOSE | Functional | State vector decomposition |
CONTEXT_PIPELINE | Imperative | Sequential measurement with ordering test |
BELL_TEST | Declarative / Specification | CHSH inequality test |
INTERFERENCE_SCAN | Dataflow / Pipeline | Interference detection |
BAYESIAN_COLLAPSE | Reactive / Event-driven | Bayesian updating with collapse |
OBSERVER_OPTIMIZE | Constraint programming | Observer-dependent collapse |
Each program is a structured prompt with typed inputs and outputs, assertions (like normalization checks), and control flow. They represent the next step beyond individual prompts: composable, verifiable semantic operations. Two are shown in full below.
# Sequential measurement with commutativity check # Input: expression, operators[] (name, instruction, strength) You are executing CONTEXT_PIPELINE. -- Initialize state LET state = superposition_decompose({{expression}}).state_vector LET trace = [] -- Forward pass: apply operators in given order FOR i = 0 TO LENGTH(operators) - 1: LET op = operators[i] PRINT "[Step {i}] Applying: {op.name} -- '{op.instruction}'" LET new_state = APPLY(op, state) LET snapshot = StateSnapshot( step = i, operator_applied = op.name, dominant_meaning = ARGMAX(new_state, by=weight), distribution = new_state, information_lost = DIFF(state, new_state) ) APPEND(trace, snapshot) state = NORMALIZE(new_state) -- irreversible -- Commutativity check IF check_commutativity AND LENGTH(operators) >= 2: LET reverse_state = superposition_decompose({{expression}}).state_vector FOR i = LENGTH(operators) - 1 DOWNTO 0: reverse_state = NORMALIZE(APPLY(operators[i], reverse_state)) fidelity = |<state | reverse_state>|^2 IF fidelity < 0.99: PRINT "WARNING: Operators do NOT commute." PRINT " Forward: {state.dominant_meaning}" PRINT " Reverse: {reverse_state.dominant_meaning}" PRINT " Fidelity: {fidelity}" PRINT " -> Ordering matters. [A,B] != 0" RETURN (trace, fidelity) # Example: 3 operators on "The model is overfitting the data" # Op1: "You are a senior ML engineer" (persona) # Op2: "Explain to a non-technical PM" (audience) # Op3: "Max 2 sentences" (format) # Forward: "Our AI is memorizing examples instead of learning..." # Reverse: "Keep it brief: the ML model is overfitting..." # Fidelity: 0.42 -> ordering matters
# 3-stage Bayesian updating with collapse detection # Input: observation, evidence[] (description, relevance) You are executing BAYESIAN_COLLAPSE. -- Initialize prior from observation LET state = PRIOR({{observation}}) PRINT "Initial superposition: {state}" PRINT "Entropy: {ENTROPY(state)}" -- Reactive event loop ON EACH event IN evidence: PRINT "--- EVENT: {event.description} ---" FOR EACH h IN state.hypotheses: h.likelihood = P(event | h.cause) PRINT " P('{event}' | {h.cause}) = {h.likelihood}" -- Bayesian update: posterior = prior * likelihood / Z FOR EACH h IN state.hypotheses: h.posterior = h.prior * h.likelihood NORMALIZE(state) EMIT UpdateLog(event, prior, likelihoods, posterior, entropy_before, entropy_after) IF ENTROPY(state) < 0.5: PRINT "** SUPERPOSITION COLLAPSED **" PRINT "Dominant cause: {ARGMAX(state)}" PRINT "Confidence: {MAX(state.posteriors)}" BREAK IF MAX(state.posteriors) > 0.90: PRINT "** NEAR-EIGENSTATE: {ARGMAX(state)} at {MAX(state)} **" -- Recommend next measurement LET remaining_entropy = ENTROPY(state) IF remaining_entropy > 0.5: LET best_test = ARGMAX over possible tests t: EXPECTED_ENTROPY_REDUCTION(state, t) PRINT "Recommended next measurement: {best_test}" RETURN (state, trace) # Example: "API returns 500 errors intermittently" # Prior: db_overload 0.25, memory_leak 0.20, race_condition 0.18, ... # Event 1: "Errors spike during business hours" -> db_overload rises # Event 2: "Memory usage is stable" -> memory_leak drops to 0.02 # Event 3: "Errors correlate with cron job" -> db_overload -> 0.61 # Recommendation: run slow query log during next cron window
Meaning is not a property of words. It's a physical process.
Try the prompts above. Measure the non-commutativity of your own instructions. Run the CHSH test on your favorite ambiguous expression. Watch interference create meanings that no single context could produce.
The mathematics is identical to quantum physics. The predictions are testable. The engineering is practical.
Share this post if it changed how you think about prompts.